Abstract
- Batch Norm은 layer’s input distribution의 변화를 통제해서 “internal covariate shift”를 줄이는 효과가 있다는게 일반적인 믿음
- 본 연구에서는 Layer inputs의 distrubutional stability가 batch Norm의 성공에 영향을 끼치지 않고, Batch Norm의 훈련과정이 loss landscape를 smoother 하게 만든다는 것을 보여준다.
- 이 smoothness는 gradient의 bahavior를 좀 더 predictive and stable하게 유도한다.
1 Introduction
Batch Norm은 Layer의 input 분포의 two moment (mean and variance) 를 통제하여, neural networks를 훈련한다.
현재 대부분은 Batch Norm의 성공이 internal covariate shift (ICS)을 완화하는데 있다고 믿는다.
그러나 본 논문에서는 그 믿음을 지지하는 구체적은 증거가 거의 없다는 것을 보여주고, ICS와 성능 사이에 관계가 없다는 것을 보인다.
Our Contributions.
Batch norm이 network를 훈련하는데 있어서 어떤 부분에 영향을 끼치는지 식별한다.
식별한 첫번째는
1) loss landscape를 좀 더 smooth하게 만든다.
- 이 것은 더 넓은 범위 learning rate를 사용할 수 있다는 것을 암시한다.
2) loss landscape를 smooth하게 만드는 것은 Batch Norm 뿐 아니라, 다른 natural normalization 기법도 유사한 효과를 가졌다.
2 Batch normalization and internal covariate shift
Batch Norm은 학습하는 동안 네트워크 layer의 각각의 activation의의 평균과 분산을 각각 0과 1로 만들어서 이용해서 stable하게 만든다.
이 Normalization 과정은 previous layer의 non-linearity 전에 적용된다.

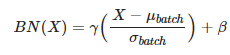
- $\gamma,\beta$는 학습 파라미터이다.
이 Batch Normalization 과정은 internal covariate shift (ICS)를 줄인다는 관점으로 많이 해석됐다.
그러나 본 연구에서는 이 관점이 틀렸다는 것을 보인다.
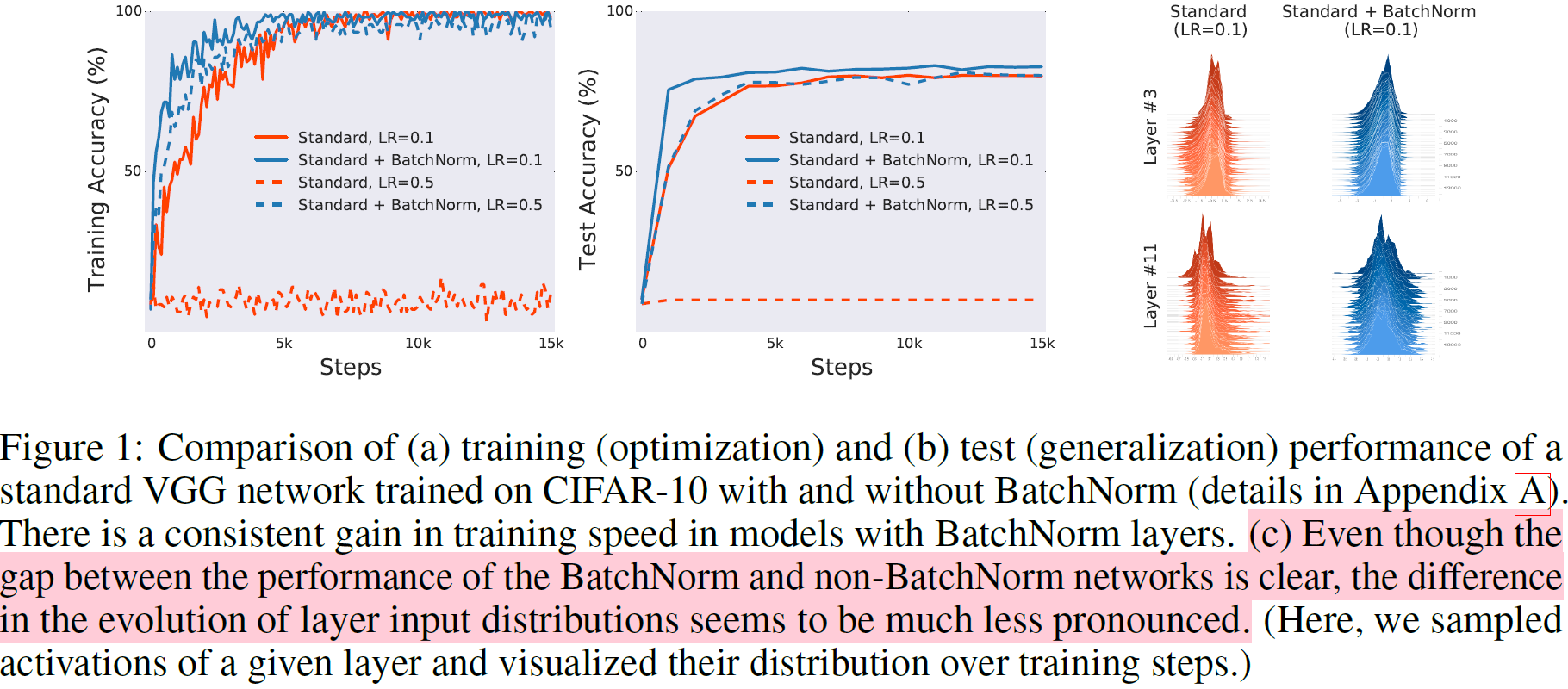
Figure (c)를 보면, BatchNorm과 non-BatchNorm의 성능 차이는 명확하지만 input distribution의 차이는 뚜렷하지 않다
이 관측은 두 가지 질문을 도출하게 한다.
1) BatchNorm의 효과는 internal covariate shift(ICS)와 관련이 있는가?
2) BatchNorm의 레이어 입력 분포 안정화가 ICS를 줄이는 데에도 효과적일까?
2.1 Does BatchNorm’s performance stem from controlling internal covariate shift?
On Large-Batch Training for Deep Learning 에서 layer input의 평균과 분산을 통제하는 것은 훈련 성능에 직접적으로 연관이 있다고 주장했다.
그러나 이 주장을 입증할 수 있을까?
이를 위해서 평균이 0이 아니고, 분산이 1이 아닌 분포로 Sampling된 Noise를 각 sample에 대한 이미 batch normalized된 activation에 추가
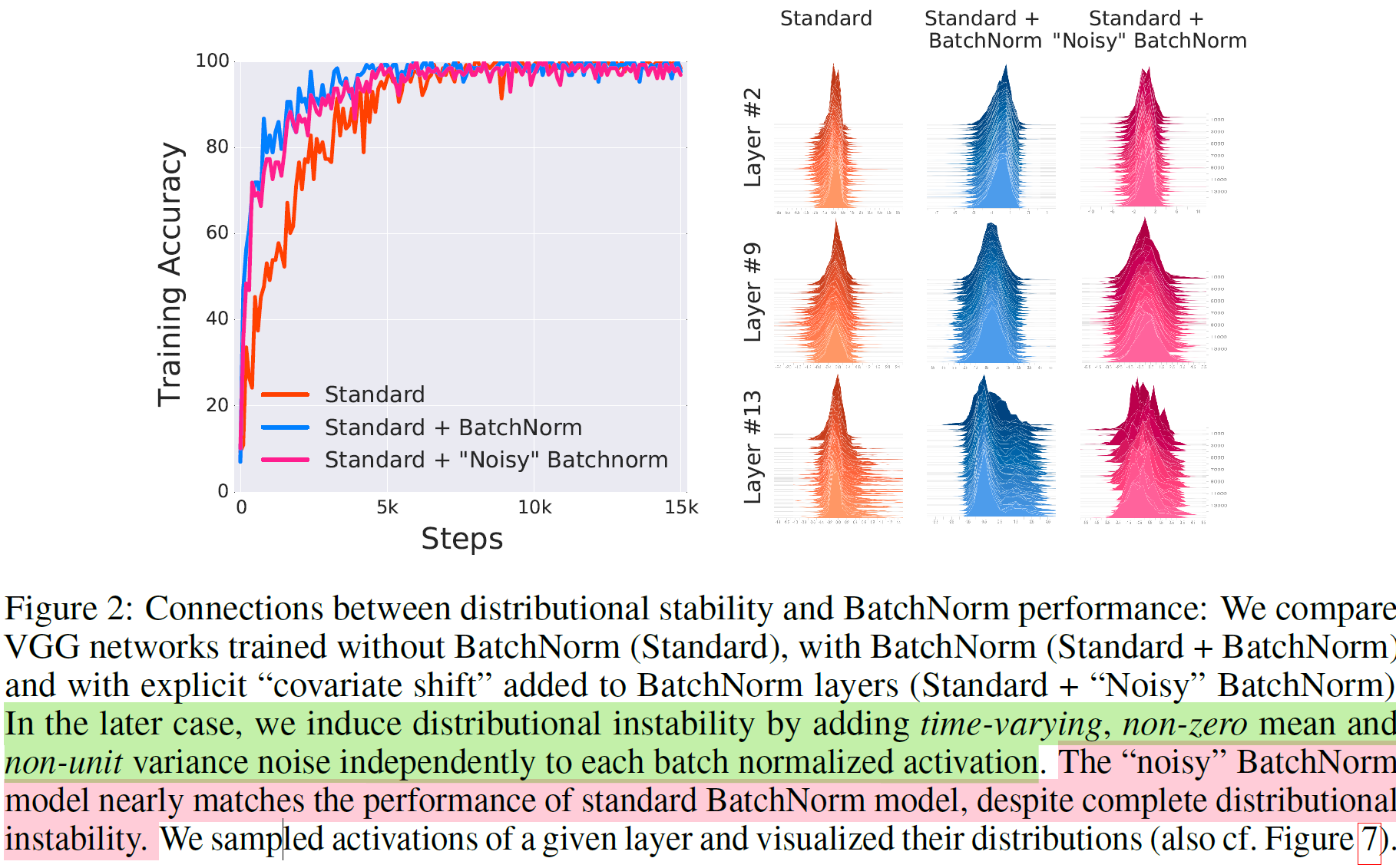
Noisy BatchNorm model이 분포 instability에도 불구하고, 성능차이가 없다.
이 발견은 BatchNorm이 input distribution의 stability를 증가시켰기 때문에 성능이 좋아졌다라고 주장하기 어렵다
2.2 Is BatchNorm reducing internal covariate shift?
Section 2.1에서 ICS는 성능에 직접적으로 연관이 없다는 것을 증명했다.
하지만, 보다 넓은 관점에서 training performance와 연관된 internal covariate shift(ICS)를 새롭게 정의할수 있을까?
논문에서는 "훈련에서 가장 자연스로운 목적에 해당하는 부분은 gradient"임을 언급
layer내의 parameters가 이전 layer의 update영향으로 얼마큼 조정해야하는지 측정하기 위해서는 이전 layer가 update되기 전과 후의 gradient간의 차이를 구해야한다.
(이전 layer가 update 되기 전 - 이전 layer가 update 된 후) 를 관찰
본 논문의 새로운 ICS 정의
$$
||G_{t,i}-G'_{t,i}||_2
$$
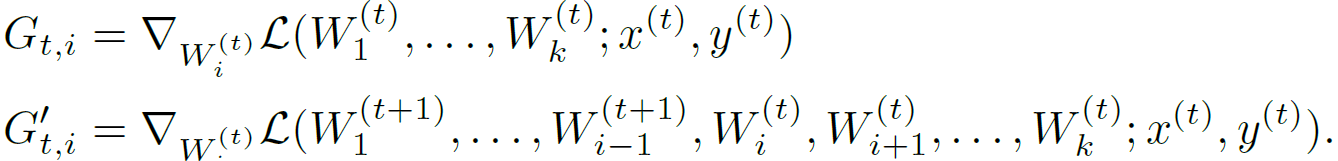
- layer $k$
- time $t$에서 input-label pairs의 batch $(x^{(t)}, y^{(t)})$
- $G_{t,i}$는 layer parameter의 gradient
- $G'_{t,i}$는 $(t+1)$번째에서 layer parameter의 gradient
- $||G_{t,i}-G'_{t,i}||_2$는 input 변화에 의해서 원인이 되는 $W_i$의 optimization landscape에서 변화를 반영
새롭게 정의한 ICS는 측정

BatchNorm의 전통적인 이해는 네트워크에 BatchNorm layer를 추가하면 $G$와 $G'$ 사이에 상관관계가 증가해야하지만 ICS는 줄어들고 있다.
즉, 비록 BatchNorm이 성능이 꾸준히 증가하지만 , $G$와 $G'$이 거의 상관관계가 없다는 것을 보인다.
이것은 BatchNorm이 여전히 internal covariate shift를 줄이지 못하는 것을 보인다.
3 Why does BatchNorm work?
BatchNorm은 ICS와 상관없지만, training process를 크게 증가했다. 이것을 어떻게 설명할 수 있을까?
원본논문에서는 BatchNorm의 추가적인 특성으로 gradient 폭주나 소실을 방해한다고 했지만 본 논문에서는 좀 더 근본적인 요소를 탐지한다
3.1 The smoothing effect of BatchNorm
본 논문에서는 BatchNorm의 핵심요소는 landscape를 smooth하게 만든다고 주장한다.
Lipschitznesss는 loss가 작은 비율로 변하고 Gradient의 크기가 작다는 것을 뜻하는데, BatchNorm’s reparamterization은 loss 함수의 gradient를 더욱 더 Lipschitz하게 만든다.

즉, loss는 훨씬 더 나은 "효과적인" $\beta$-smoothness 나타냄

loss function은 non-convex하고 많은 flat regions, sharp minima, kinks를 가지고 있는데, 이 것은 gradient descent-based training 알고리즘을 unstable하게 만든다 (ex, gradient 폭주, gradient 소멸) 그리고 이것은 learning rate, 초기값을 선택하는데 크게 민감하게 만든다.
함수의 그라디언트가 Lipschitz 연속성을 가지면, 그라디언트 방향이 급격히 변하지 않기 때문에,
최적화 알고리즘에서 더 큰 스텝을 취하더라도 그 방향이 여전히 신뢰할 만하다
이는 우리가 그라디언트 기반의 최적화 알고리즘을 사용할 때 안정성과 신뢰성을 높여줍니다.
3.2 Exploration of the optimization landscape
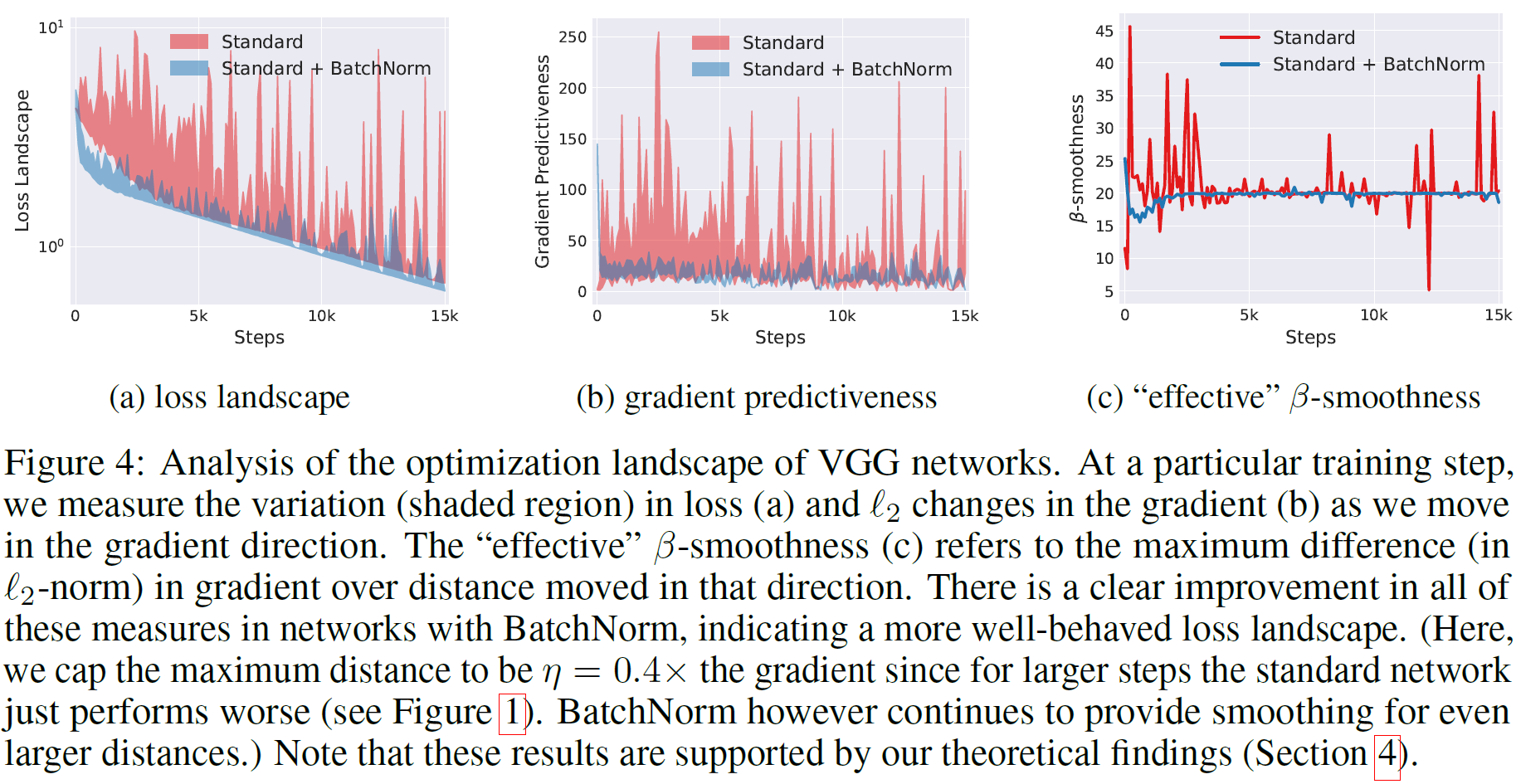
- Loss Function의 Lipschitzness 향상. loss의 변화도가 낮아짐을 의미합니다.
- gradients의 Lipschitzness 향상. grad의 크기가 작아짐을 의미합니다.
3.3 Is BatchNorm the best (only?) way to smoothen the landscape?
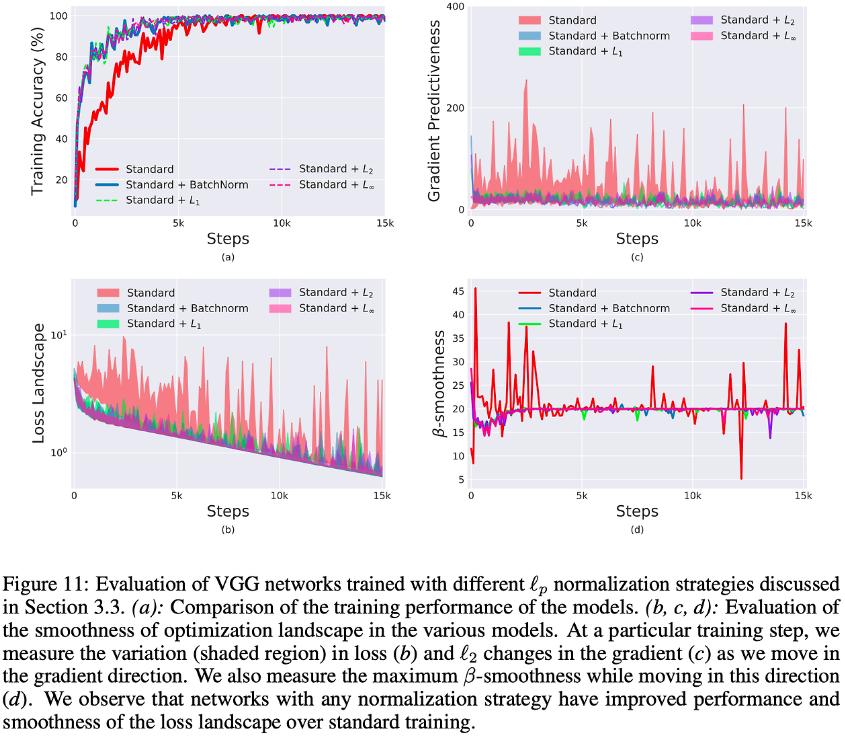
Smoothening effect는 BatchNorm만의 유일한 특징일까? 아니면 다른 normalization schemes를 사용했을 때 같은 효과를 얻을 수 있을까?
4 Theoretical Analysis
BatchNorm이 Optimization landscape에 근본적인 효과가 있다는 것을 이론적인 관점에서 분석한다.

4.2 Theoretical Results
Loss 함수의 Lipschitzness를 포착하는 Gradient magnitude $||\nabla_{y_j}\mathcal{L}||$에 관심을 둔다
Loss의 Lipschitz constant는 Optimization에 핵심적인 역할을 하는데, 본 논문에서는 batch-normalized landscape가 좀 더 나은 Lipschitz constant를 나타내는 것을 보여준다.
“gradient deviates"는 최적화 과정에서 그라디언트가 예상되는 방향에서 벗어나는 정도를 의미하며, Lipschitz 연속성은 이러한 벗어남을 줄여줌으로써 학습의 안정성과 효율성을 높이는 데 중요한 역할
Reference
https://arxiv.org/abs/1805.11604
How Does Batch Normalization Help Optimization?
Batch Normalization (BatchNorm) is a widely adopted technique that enables faster and more stable training of deep neural networks (DNNs). Despite its pervasiveness, the exact reasons for BatchNorm's effectiveness are still poorly understood. The popular b
arxiv.org
https://deepseow.tistory.com/2
[논문 리뷰] How Does Batch Normalization Help Optimization?, 2018
배치 정규화에 대한 고찰. (How Does Batch Normalization Help Optimization?, 2018) 개요 배치 정규화는 DNN 학습의 속도 향상 및 안정에 좋은 영향을 줍니다. 이와 같은 현상에 대한 이유와 널리 퍼져있는 오해
deepseow.tistory.com
https://eehoeskrap.tistory.com/430
[Deep Learning] Batch Normalization (배치 정규화)
사람은 역시 기본에 충실해야 하므로 ... 딥러닝의 기본중 기본인 배치 정규화(Batch Normalization)에 대해서 정리하고자 한다. 배치 정규화 (Batch Normalization) 란? 배치 정규화는 2015년 arXiv에 발표된 후
eehoeskrap.tistory.com
https://heytech.tistory.com/438
[Deep Learning] Batch Normalization(배치 정규화) 개념 및 장점
📌 들어가며 본 포스팅에서는 딥러닝 Generalization 기법 중 하나인 배치 정규화(Batch Normalization)에 대해 알아봅니다. 먼저, 데이터 정규화의 필요성에 대해 알아보고, Batch Normalization의 등장 배경인
heytech.tistory.com
'Deep Learning' 카테고리의 다른 글
| Normalized Gradient Descent (0) | 2024.05.29 |
|---|---|
| Two Natural Weaknesses of Gradient Descent (0) | 2024.05.29 |
| AdaNorm: Adaptive Gradient Norm Correction based Optimizer for CNNs (0) | 2024.05.09 |
| Domain Generalization via Gradient Surgery (0) | 2024.01.17 |
| Penalizing Gradient Norm for Efficiently Improving Generalization in Deep Learning (0) | 2023.11.21 |