Abstract
- Visual prompts는 high-dimension additive vector와 labeled data에 의존
- 본 논문에서는 Convolution visual prompts(CVP)를 소개
Method
본 논문에서는 convolution으로 생성한 prompt를 통해 deep model을 instruct하는 방법론을 소개한다
$$
x=x+\lambda \text{conv}(x,k)
$$
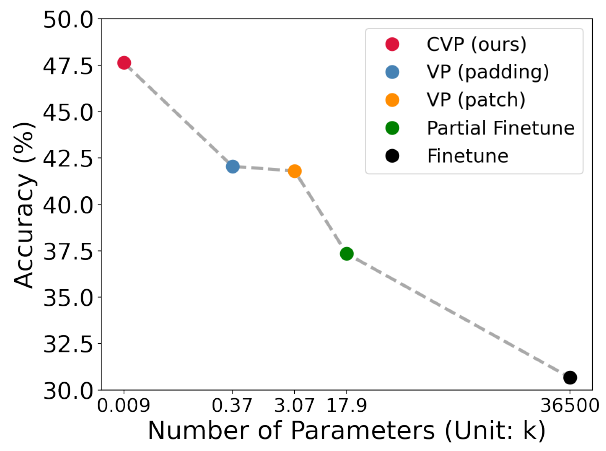
Convolution prompt의 주요 장점은 patch prompt와 padding prompt와 같은 전통적인 prompt보다 parameter수보다 적다는 것이다.
[전체 알고리즘]

[Flow of CVP]

[Low-Rank Visual Prompt]
- CNN을 이용하여 Prompt를 생성하는대신 Image를 특이 값 분해를 하여 초기 visual prompt를 결정

Experiment
4.2 Experimental Results
[Training Cost v.s. Different Kernel Size]

[Training Time v.s. Number of Adapt Iteration]

[Number of Trainable Parameters]
Reference
https://arxiv.org/abs/2303.00198
Convolutional Visual Prompt for Robust Visual Perception
Vision models are often vulnerable to out-of-distribution (OOD) samples without adapting. While visual prompts offer a lightweight method of input-space adaptation for large-scale vision models, they rely on a high-dimensional additive vector and labeled d
arxiv.org
'Prompt learning' 카테고리의 다른 글
| Understanding and Improving Visual Prompting: A Label-Mapping Perspective (0) | 2025.01.09 |
|---|---|
| Visual Prompt Tuning (0) | 2024.12.18 |
| Unleashing the Power of Visual Prompting At the Pixel Level (0) | 2024.12.12 |
| ADAPTING TO DISTRIBUTION SHIFT BY VISUAL DOMAIN PROMPT GENERATION (0) | 2024.12.05 |
| From Visual Prompt Learning to Zero-Shot Transfer: Mapping Is All You Need (0) | 2024.11.20 |