시사점
- Figure 2(d) 그림을 참조하면 좋을거 같다
- Inter-Class Feature Distance도 ablation 실험에 추가하면 좋을거 같다
- “$\gamma$ remains frozen during the first inner loop”라는 표현이 좋다
Abstract
- 본 논문에서는 fixed hyperparameters (intra-layer positions, layer depth, and scaling factors)가 Parameter-efficient finetuning (PEFT) techniques의 성능을 저하한다는 것을 관측
- 이 문제를 다루기 위해서 PEFT의 3가지 핵심 요소를 조정하는 MetaPEFT 방법론을 제안
- MetaPEFT는 Remote Sensing (RS) 데이터에서 module insertion, layer selection, module wise learing rates를 dynamic하게 조정
1. Introduction
- full fine-tuning과 비교하여 PEFT는 foundation models에 대한 more efficient adaptation method이다
- PEFT의 일반적인 아이디어는 pre-trained weight를 frozen하고 일부 파라미터 집합만 업데이트 하는 것이다
- 본 논문에서는 먼저 대표적인 PEFT 방법이로부터 두가지 핵심을 관측했다
- additive method가 non-additive method보다 성능이 좋았다
- additivei method가 더 나은 tail-calss feature discrimination을 달성했다
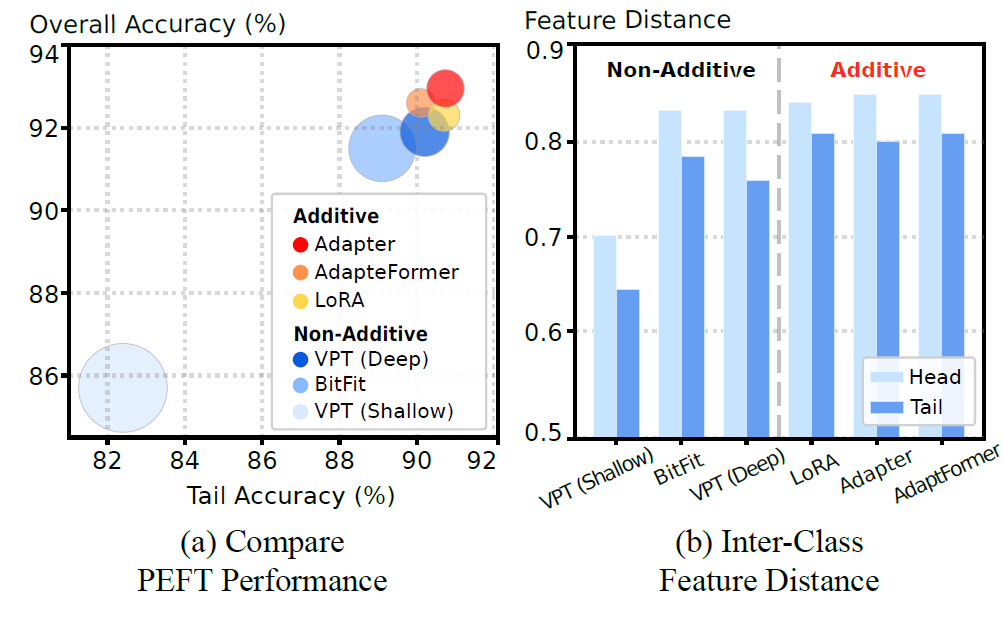
- 그리고 additivei method는 3가지 핵심 Hyperparameter를 기반으로 달라진다는 것을 발견
- Intra-Bloack Position과 Block Depth에 따라 optimal performance가 달랐다
- Intra-Bloack Position과 Scaling Factor의 상관관계가 non-monotonic했다

- 이 관측을 기반으로 PEFT을 위한 efficient end-to-end hyperparameter optimization을 제안
- 구체적으로, PEFT-specific hyperparameters의 통합된 modulator를 도입
- 그리고 modulatore를 bi-level optimization으로 학습

3. Method
3.1. PEFT and Its Hyperparameters
- non-additive method는 pre-trained parameter $\theta$를 freeze하고 fixed parameter $\phi$를 업데이트한다
- 단, $\phi \in \theta$, $\text{dim}(\phi) << \text{dim}(\theta)$

- 반면에, Additive method는 new parameter $\phi$를 선택된 위치에 도입하여 $\theta$를 조정한다
- $\mathbb{1}_p \in {0,1}$
- $\Delta(x; \phi)$는 $\phi$로 파라미터화된 additive PEFT 모듈
- $\alpha$는 scaling factor

3.2. Limitations of Manual Optimization
- $\mathbb{1}_p \in {0,1}$와 이산적인 블록 깊이 $d$는 이산적이고 scaling factor $\alpha$는 연속적이기 때문에 한번에 미분할 수 없다
3.3. Auto Optimization via Meta-Learning
Unified Modulator.
- 본 논문에서는 식 (2)를 식 (6)으로 수정한다
- 그리고 $\gamma$를 학습가능한 변수로 둔다 (unified modulator)

Bi-Level Optimization Framework.
- 최종 목적 함수

- Inner-loop
- $\gamma$는 고정하고 additive module만 학습한다

- outer-loop
- $\gamma$를 학습한다.
- 사용하는 데이터는 figure (d)를 참조

Reference
CVPR 2025 Open Access Repository
MetaShadow: Object-Centered Shadow Detection, Removal, and Synthesis Tianyu Wang, Jianming Zhang, Haitian Zheng, Zhihong Ding, Scott Cohen, Zhe Lin, Wei Xiong, Chi-Wing Fu, Luis Figueroa, Soo Ye Kim; Proceedings of the IEEE/CVF Conference on Computer Visio
openaccess.thecvf.com
'Test-time adaptation' 카테고리의 다른 글
| SoTTA: Robust Test-Time Adaptation on Noisy Data Streams (0) | 2025.09.29 |
|---|