Abstract
- 본 논문에서는 pretrained text-to-image diffusion model에 공간 조절 제어 (spatial conditioning controls)를 추가하는 neural network architecture인 ControlNet을 제안
- ControlNet은 large diffusion model을 lock하고, encoding layer를 복사하여 다양한 conditional control을 학습한다
- Neural Network는 “zero convolution” (zero-initialized convolution layers) 을 사용하여 parameter를 zero로부터 점진적으로 update한다
- 이렇게 하여 harmful noise가 finetuning에 영향을 주지 않도록 한다.
1. Introduction
- 우리는 지금 text prompt를 입력하여 시각적으로 멋진 이미지를 만들 수 있다
- 그러나 text-to-image model은 text prompt만을 사용하여 image의 spatial composition을 제공하는데 한계가 있다
- 그렇다고 large text-to-image diffusion model을 end-to-end 방식으로 다시 훈련하는 것은 문제가 있다
- 일반적으로 specific conition을 위한 training data는 text-to-image training보다 작다
- 그렇기 때문에, 새롭게 fine-tuning하는 것은 overfittion이나 catastrophic forgetting 문제가 발생할 수 있다
- 그러므로, 본 논문에서는 pretrained text-to-image diffusion model을 위해 conditional control을 학습하는 end-to-end neural network를 제시
3. Method
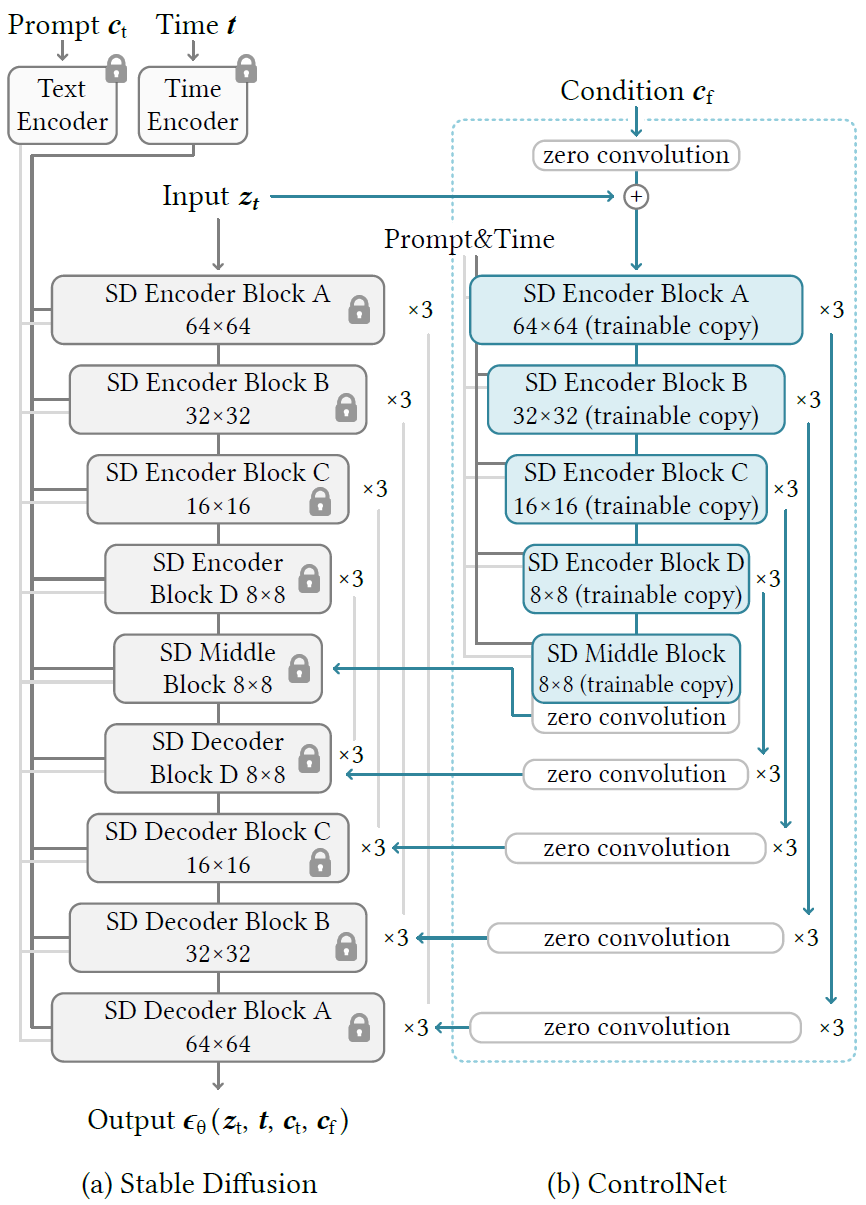
3.1. ControlNet
- 아래 그림 (a)와 같이 trained model $\mathcal{F}(\cdot;\Theta)$가 있을 때,
- 그림 (b)와 같이 original block의 parameter $\Theta$를 lock(freeze) and trainable copy한다
- trainable copy는 external conditional vector $c$를 input으로 취한다

- trainable copys는 zero convolution layer $\mathcal{Z}(\cdot;\cdot)$와 연결
- $\mathcal{Z}$는 $\Theta_1,\Theta_2$로 이루어짐

- zero convolution layer $\mathcal{Z}(\cdot;\cdot)$ 는 zero로 초기화하여, 훈련 초반에는 input image를 trainable copy $\mathcal{F}(\cdot;\Theta)$가 그대로 받게하여 pretrained model의 능력을 유지하게 한다
3.2. ControlNet for Text-to-Image Diffusion
4. Experiments

Reference
https://arxiv.org/abs/2302.05543
Adding Conditional Control to Text-to-Image Diffusion Models
We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text-to-image diffusion models. ControlNet locks the production-ready large diffusion models, and reuses their deep and robust encoding layers pr
arxiv.org
'Diffusion' 카테고리의 다른 글
| Diffusion 수식 (0) | 2025.12.02 |
|---|