Introduction
- Generative AI 분야에 디퓨전이 등장하여 Text-to-image (T2I) synthesis의 큰 진보를 이뤄냈다
- T2I는 textual prompt로 high-quality image를 생성하는 것이다
- T2I 성공을 기반으로, text-to- video (T2V) 생성과 editing 연구가 탐구됐다
- 초기 시도는 pixel or latent space에서 T2V difussion 모델을 훈련햇다
- 그러나 데이터셋이 너무 크고 훈련비용이 컸다
- 최근에는 pre-trained T2V diffusion 모델을 활용한 Training-free 기법 등장
- 그러나 frame 별로 일관성 있는 coherent motion를 달성하기 어렵다, 특히 모든 프레임에 single user prompt를 사용할 때
- 이 문제를 다루기 위해, LLMs 모델을 활용하여, single user prompt로 부터 frame-by-frame로 description을 생성하는 연구가 등장
- motion incoherence의 문제가 발생
- 본 논문에서는 GPT-4, Blaender Simulator, Stable diffusion을 이용하여 video synthesis의 quality를 높인다.
[Contribution]
- Training-free
- LLM-driven physics scripting
- Blender의 강력한 시뮬레이션 직접 활용
- SDXL 기반 고품질 렌더링
- 실제 Physics-aware한 영상 생성
- 매우 높은 temporal coherence
Method

- text prompt로 GPT-4를 통해 Blender 코드를 생성한다
- Blender는 유니티와 같은 physical simulator이다
- 생성된 코드를 Blender Physics Engine에 넣는다.
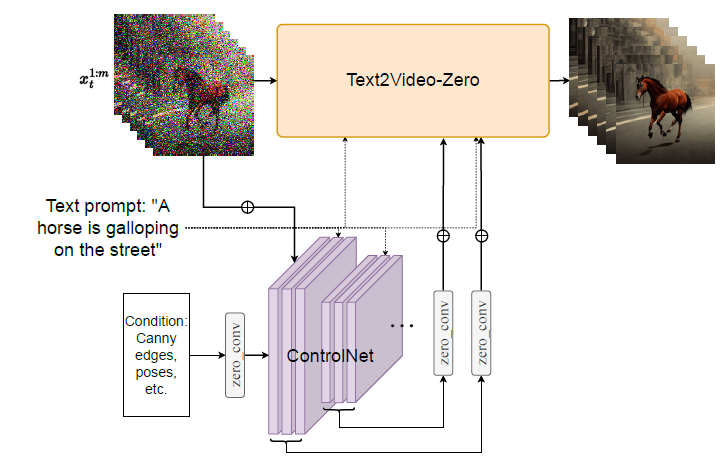
- Edge Maps과 Depth Maps을 추출한다
- ControlNet을 이용하여, Text prompt와 추출된 Edge Maps과 Depth Map을 ControllNet을 이용하여 Stable diffusion 입력으로 활용한다.
[참고] ControllNet
- 원래 Stable Diffusion은 depth나 edge를 입력으로 받지 않는다.
- Stable Diffusion은 기본적으로 **오직 텍스트(prompt)만 입력으로 받는 text-to-image 모델이다.**
- 그런데 GPT4Motion 논문에서는 Stable Diffusion이 depth/edge map을 입력으로 받도록 만든 것 이다.
- 이건 ControlNet 덕분이다.
Reference
https://arxiv.org/abs/2311.12631
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning
Recent advances in text-to-video generation have harnessed the power of diffusion models to create visually compelling content conditioned on text prompts. However, they usually encounter high computational costs and often struggle to produce videos with c
arxiv.org