용어정리
[interaction data]
- 에이전트가 실제로 행동(Action)을 해야만 생기는 데이터
✔ 로봇이 물체를 잡아본다 → 성공/실패 데이터
✔ 로봇 팔이 공을 밀어본다 → 공이 어떻게 움직였는지 trajectory 기록
✔ RL agent가 게임에서 점프한다 → 다음 상태(state’)와 reward 얻음
✔ self-driving car가 steering 하면서 도로 정보를 기록
| 분야 | interaction 데이터의 예 |
|---|---|
| 로봇 | 로봇 팔이 “잡기, 밀기, 회전시키기”를 시도한 로그 |
| RL | state–action–reward–next state(SARS) |
| 게임 | 에이전트가 joystick 입력 → 게임 상태 변화 |
| 자율주행 | steering, brake → 차량 주변 상태 변화 |
[Something-Something v2]
- 주로 비디오 행동 인식 분야의 모델 성능을 평가하는 데 사용되는 대규모 데이터셋
Abstract
- ‘라벨 없이 관찰만 해도 세계에 대한 중요한 지식(배경지식)을 배울 수 있다’는 self-supervised 학습의 가설을 바탕으로, 환경을 이해하고 예측할 수 있는 world model을 설계
- 즉, 사람처럼 그냥 비디오를 관찰하는 것만으로도 세상의 규칙성을 배울 수 있다 는 가정.
- 구체적으로, 본 논문에서는 Interation data를 사용하지 않는다
- 직접 상호작용(interaction)을 하지 않아도,인터넷이나 실제 비디오를 ‘보기만’ 해도 세계의 기본 구조(dynamics, physics-like patterns)를 배울 수 있다
- 인간이 물리 법칙을 이해하지 않고, 어릴 때부터 “보고 관찰”하면서 세계의 기본 구조(dynamics, physics-like patterns)를 배울 수 있듯이
- V-JEPA도 마찬가지로 수많은 비디오 (internet-scale video)를 self-supervised로 관찰 하는 것만으로 세계에 대한 “배경지식(background knowledge)”을 얻게 된다는 의미.
1. Introduction
- JEPA 방식은 두 가지 어려운 문제를 동시에 해결해야 한다:
- Representation 학습(시각·동적 정보 인코딩)
- Prediction 학습(미래 latent를 예측, temporal dynamics 학습)
- 그러나, 이 둘을 한 번에 end-to-end로 학습하면:
- 비디오 long-range prediction이 불안정하고
- representation collapse 위험이 큼
- training dynamics가 매우 불안정함
- 그러므로, 안정적으로 학습하기 위해 단계 별로 따로 최적화(stage-wise) 하는 전략을 사용함.

- [Stage 1] Video Encoder Pretraining (Self-supervised Representation Learning)
- 비디오에서 temporal + spatial structure를 풍부하게 인코딩하는 encoder 학습
- 즉, 고품질 video representation backbone 확보
- 하지만, 이 단계는 future prediction을 학습하지 않고, 오직 representation quality 에 집중함.
- [Stage 2] Predictor Training (Future Latent Prediction / Dynamics Modeling)
- Stage 1의 encoder로 표현된 latent를 입력으로 받아 미래 latent를 예측하는 dynamics model 학습
- 즉, 덮개(masked)된 영역이나 미래의 latent vector를 예측
- 세계의 temporal consistency, intuitive dynamics, motion priors를 학습함
- 이 단계에서 사실상 intuitive physics를 암묵적으로 학습하는 단계
- [Stage 3] Joint Finetuning or Task Adaptation (Optional)
- 해당 stage는 Optional finetune단계라고 할 수있음
- video understanding
- future prediction
- planning (RL agent)
- visual control 등에서 end-to-end로 약하게 미세조정(finetune)할 수 있음.
- 엄밀하게 말하면, V-JEPA 2는 다음의 두 단계(stage-wise training)을 분리해 안정적으로 world model을 학습한다:
- Encoder pretraining
- masked JEPA objective
- robust video representation 학습
- Predictor training
- encoder freeze
- future latent prediction
- temporal dynamics 학습 (intuitive physics 포함)
- Encoder pretraining
2 V-JEPA 2: Scaling Self-Supervised Video Pretraining
2.1 Methodology
Mask-Denoising in Representation Space.

- masked video $x$로부터 video $y$의 representation을 예측한다
- 아래 그림의 왼쪽에 설명되어 있음
- $\Delta_y$ : learnable mask token
- $E_{\theta}(\cdot)$ : encoder
- $P_{\phi}(\cdot)$: predictor
- $sg_{\overline{\theta}}(\cdot)$: weight $\theta$의 exponential moving average $\overline{\theta}$
- representation collapse를 방해하기 위해서

- Encoder $E_{\theta}(\cdot)$와 Predictor $P_{\phi}(\cdot)$는 ViT 사용
- 참고로 ViT를 기반으로 했지만, 1D-RoPE, 등등 다양한 전략을 사용 (논문 page 5부터 참조)
3 V-JEPA 2-AC: Learning an Action-ConditionedWorld Model
- Pre-training이 끝나면 V-JEPA 2는 비디오에 missing 부분을 예측할 수 있게된다
- 하지만, 이 예측은 에이전트가 취할 수 있는 행동의 인과적 효과를 직접적으로 고려하지 않는다.
- 자세한 방법은 아래 그림과 같다
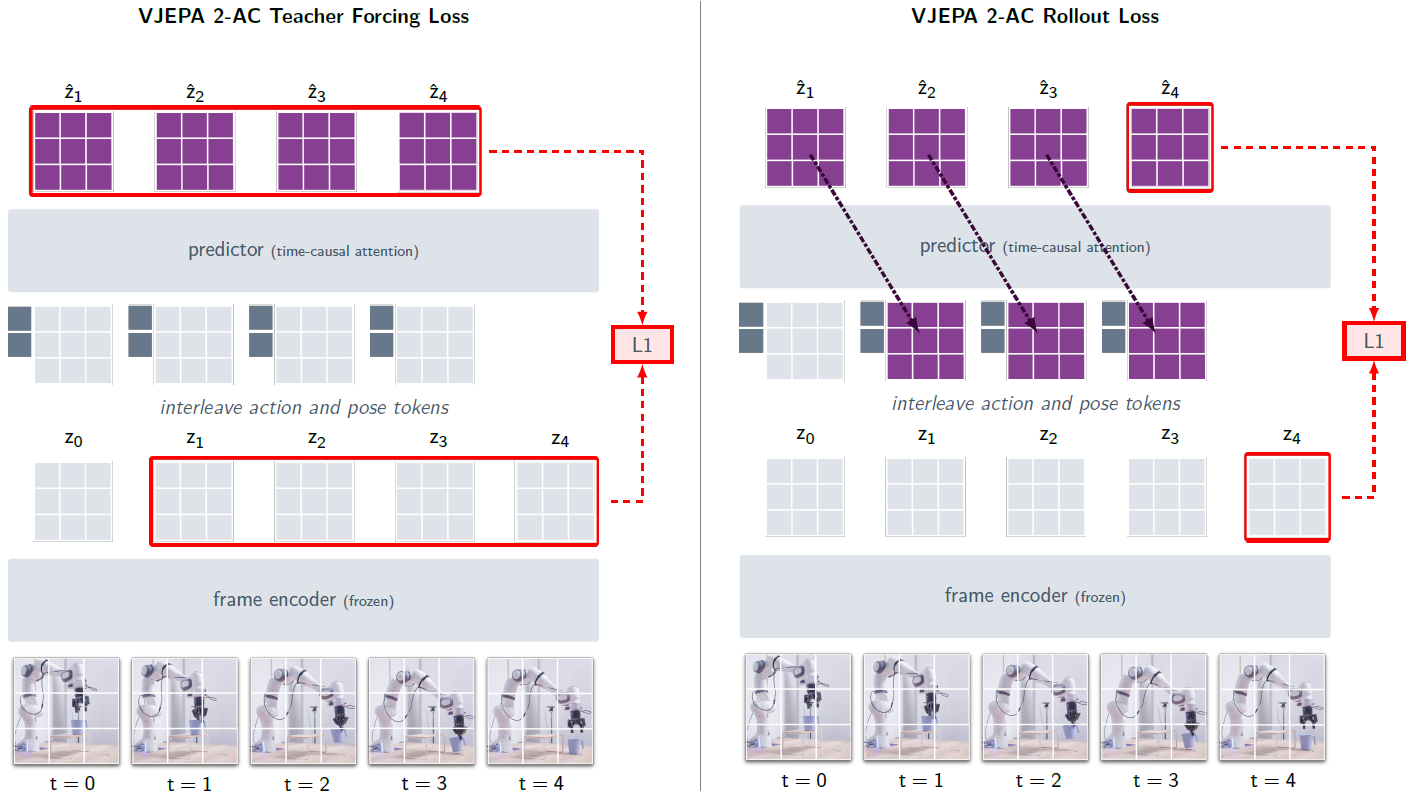
- 과거 비디오 embedding(Antecedent)에서 미래 비디오 embedding(Consequent)을 예측
✔ V-JEPA 2 = 공간적/부분적 feature 복원
✔ V-JEPA 2-AC = 시간적 미래 feature 예측 (temporal prediction)
4 Planning: Zero-shot Robot Control
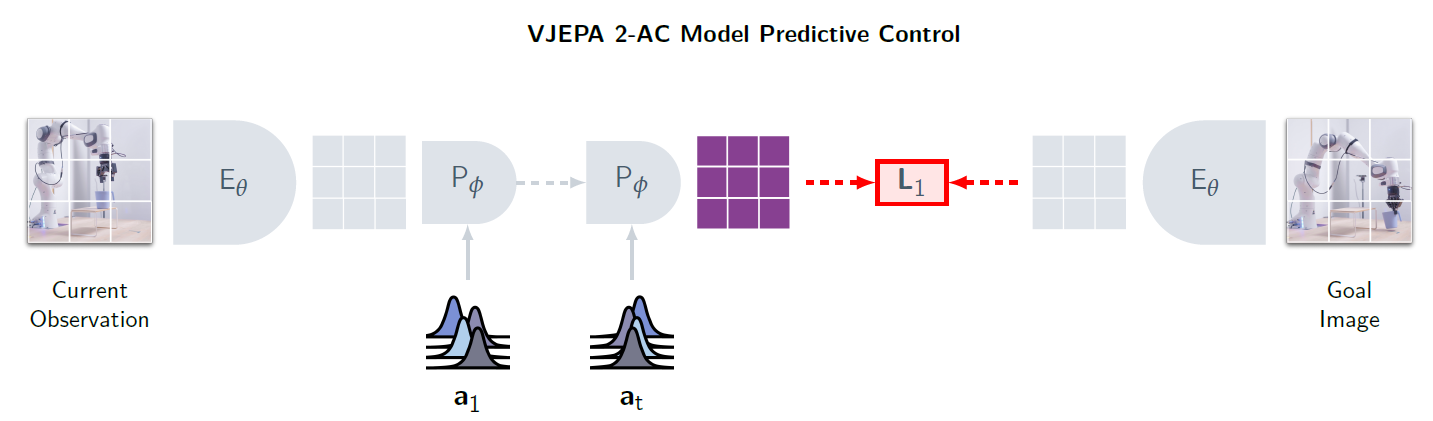
Reference
https://arxiv.org/abs/2506.09985
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories)
arxiv.org