Abstract
- Text-conditioned image-to-video generation (TI2V)는 주어진 image와 text description으로 시작하여 realistic video를 생성하는 것이 목표
- 기존 TI2V framework는
- video-text dataset으로 costly training과
- text and image conditioning을 위한 specific model design이 필요했다
- 이 논문에서는 zero-shot, tuning-free method인 TI2V-zero를 제안한다
- 어떠한 optimization, fine-tuning, exteral module 없이
- pre-trained text-to-video(TI2V) diffusion model에 제공된 이미지에 따라 조건화 될 수 있는 능력을 부여
- reverse denosing process를 수정하는 “repeat-and-slide” strategy을 제안
- frozen diffusion model이 video를 제공된 이미지로 시작하여 frame-by-frame으로 생성
1. Introduction
- TI2V는 주어진 frame $x^0$에서 시작하여, text descrption $y$를 만족하는 realistic video $\hat{\mathbf{x}}=<x^0, \hat{x}^1, ...,\hat{x}^M>$을 도출
- 현재 TI2V generation method는
- computationally-heavy training on video-text datasets
- text and image conditioning할 수 있는 specific architecture designs에 의존
- 본 논문에서는 어떠한 optimization, fine-tuning, or introduction of additional modules없이 image conditioning이 가능한 방법론을 제안
- 구체적으로 provided image $x^0$을 output latent code에 통합하여 generation process를 guide하는 방법론을 제안
- 특히 전체 video volume을 직접 생성하기보다는, frame-by-frame manner로 video를 생성하는 1) repeat-and-slide strategy를 제안
- 그리고 randomly initialized Gaussian noise로 시작하는 standard denoising sampling은 temporally inconsistent videos를 만들 수 있다.
- 그러므로 각 새로운 frame을 생성하는 동안 좀 더 suitable initial noise를 제공하기 위해 2) inversion strategy을 도입한다
- 또한, resampling technique을 적용하여 Video DM이 visual details을 보존하도록 도와줌
2. Related Work
2.1. Conditional Image-to-Video Generation
- Conditional video generation는 user-provided signals로 guide된 비디오를 생성하는 것을 목표로 한다
- text-to-video (T2V) generation
- video-to-video (V2V) generation
- image-to-video (I2V) generation
- text-conditioned image-to-video (TI2V)
- 본 논문에서는 text-conditioned image-to-video (TI2V)에 집중한다
- 기존 TI2V 프레임워크는 1) 비디오-텍스트 데이터셋에 대한 계산 비용이 많이 드는 학습과, 2) 텍스트 및 이미지 조건부 학습을 지원하는 특정 모델 설계를 요구
2.2. Adaptation of Diffusion Foundation Models
- Diffusion models (DM)은 image and video generation (T2I, T2V)분야에 성공적으로 적용되면서 visual diffusion foundation models이 주목을 받기 시작
- 이 모델들은 large scale open-domain datasets (LAION-400M and WebVid-10M)으로 훈련된다
- 그리고 획득한 지식을 다양한 downstream task에 적용하는데 적용하여 extensive labeled data에 대한 요구를 줄인다
- 예를들어, 이전 연구는 T2I 모델을 personalized image generation, image editing, image segmentation, video editing, video generation에 적용했다
- T2I 모델과 대조적으로, large-scale T2V models의 적용은 소수 연구가 진행됐다
- DynamicCrafter는 VideoCraft1을 T2V foundation model로 활용하여 open-domain TI2V generation를 제안했다
- 생성 과정을 Control하기 위해서, 그들은 처음으로 learnable image encoding network를 도입하여 주어진 image를 text-aligned image embedding space로 project했다
3. Methodology
3.1. Preliminaries: Diffusion Models
- Diffusion Models (DM)은 data distribution을 학습하기 위해 설계된 probabilistic models이다
- 여기서 Denoising Diffusion Probabilistic Models (DDPM)을 소개한다
- data distribution $z_0 \sim q(z_0)$으로부터 sample이 주어졌을 때,
- Forward diffusion process는 variance schedule $\beta_1,...\beta_T$에 따라 반복적으로 Gaussian noise를 $z_0$에 추가하여 Markov chain $z_1,...,z_T$를 생성하며

- $T$가 충분히 크면 $z_T$는 Gaussian distribution $\mathcal{N}(0,\mathbf{I})$에 수렴한
- DDPM은 $q(z_{t-1}|z_{t})$ 의 닫힌형태를 활용하여, posterior의 형태를 따라가는 generative reverse process를 학습한다
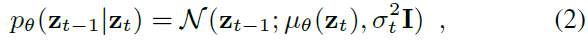
3.2. Architecture of Pretrained T2V Model
- TI2V-Zero는 3D-UNet-based denoising network로 pretrain된 T2V diffusion model $\mathcal{M}$을 기반으로 한다
Structure Overview.
- Latent Diffusion Models (LDM)과 유사하게
- T2V model $\mathcal{M}$ 은 frame auto-encoder을 통합한다
- real video $x=<x^0,x^1,...,x^K>$가 주어졌을 때,
- $\mathcal{M}$은 frame encoder $\mathcal{E}$로 video $x$를 $z=<z_0^0, z_0^1, .., z_0^K>$로 인코딩한다
- DM에 사용되는 표기법과 일관성을 유지하기 위해,
- clean video latent $z=z_0=<z_0^0, z_0^1, .., z_0^K>$
- $z_t = <z_t^0,z_t^1,...,z_t^K,>$는 $t$ steps에서 original latent sequence $z_0$에 noise를 추가한 결과를 나타낸다
- training 할 때, DM의 forward diffusion process는 initial latent sequence $z_0$에 Gaussian noise $\epsilon$을 반복적으로 추가하여 $z_T$로 transform한다
- inference 동안에는, 3D denosing U-Net $\epsilon_{\theta}$이 각 step에서 추가된 노이즈를 예측한다
- 그렇게하여, 랜덤하게 샘플링된 Gaussian noise $z_T \sim \mathcal{N}(0,I)$로부터 시작하여 clean latent sequence $\hat{z}=<\hat{z}^0_0, \hat{z}^1_0, ...\hat{z}^K_0>$을 생성할 수 있다.
Text Conditioning Mechanism.
- $\mathcal{M}$은 cross-attention mechanism을 사용하여 text-information을 guidance로써 generative process에 통합한다
- 구체적으로 $\mathcal{M}$은 pretrained CLIP model로 prompt $y$를 text embedding $e$로 인코딩한다
- 후에 text embedding $e$는 spatioal attention block 내에 multi-head attention layer의 key value로 활용하여 text feature와 $\epsilon_\theta$에 U-Net features와 통합한다
Denoising U-Net.
- Denoising U-Net $\epsilon$에는 4가지 핵심 block이 있다
- initial block
- downsampling block
- spatio-temporal block
- upsampling block.
- initial block은 input을 embedding space로 transfer하고
- downsampling and upsampling blocks은 피처 맵을 공간적으로 다운샘플링 및 업샘플링하는 역할을 한다
- The spatio-temporal block은 spatial and temporal dependencies을 capture하기 위해 설계된다
- 2D spatial convolution, 1D temporal convolution, 2D spatial attention, and 1D temporal attention로 구성된다
3.3. Our Framework

Replacing-based Baseline
- 디노이징 스텝마다,
- 첫 프레임 latent를 매 스텝마다 주어진 이미지 latent $z^0_0$으로 교체
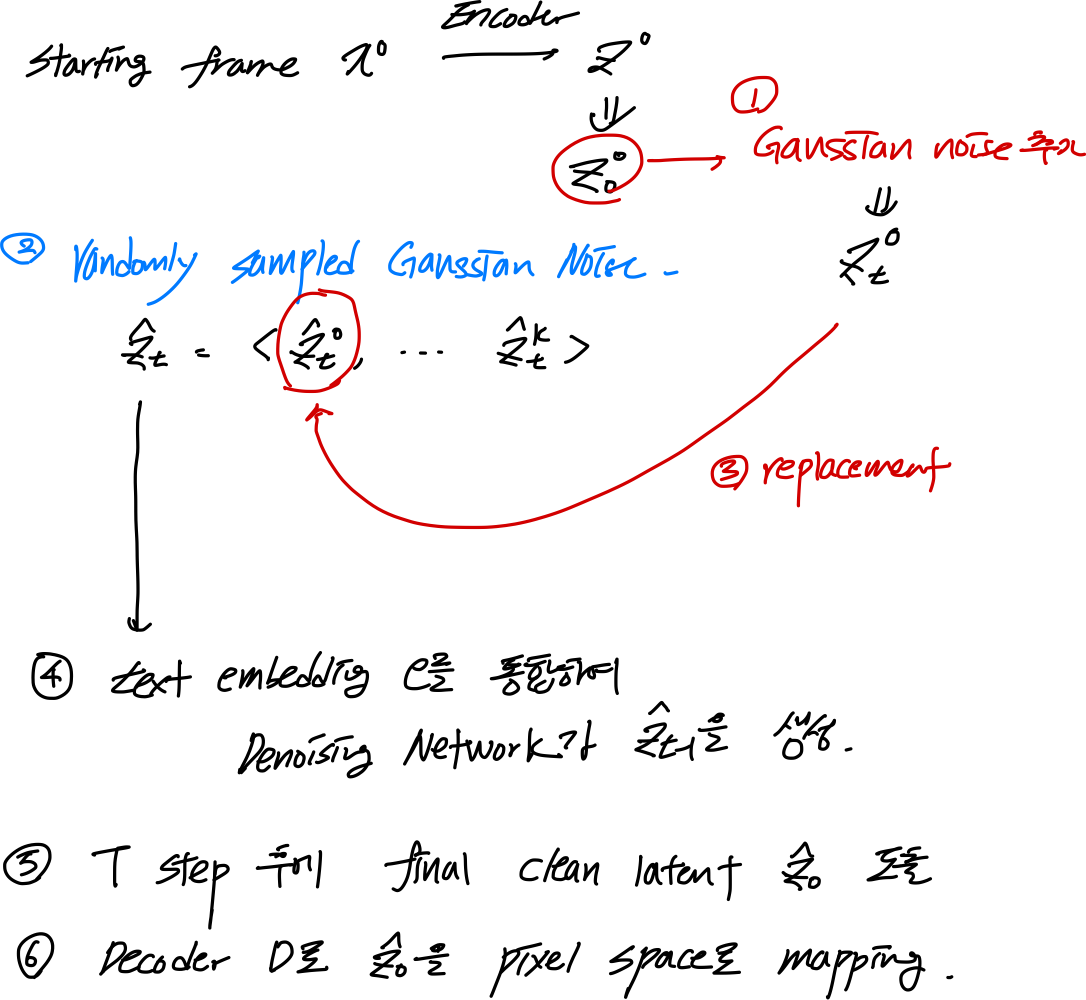
- 주의해야할 점은
- reverse diffusion을 $T$ 스텝 진행하는 동안,
- 각 디노이징 스텝 $t$ 에서 주어진 image latent에 대해 “해당 t에 대응하는 forward-noised latent를 즉석에서 계산” 해서
- 그 스텝의 입력을 교체(replace) 한다는 점이다.
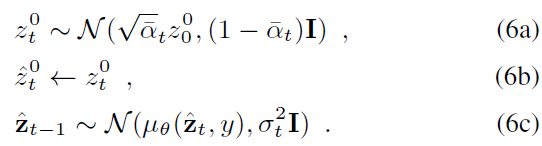
- 그러나 생각대로 안됨
- 아래 그림 두번째 행 (Video Infilling) 을 보면, replacing-based approach이 첫번째 이미지와 temporally consistent 실패
- 그러나 첫번째 frame 말고는 모두 temporally consistent를 유지

- 논문에서 temporally consistent 실패 이유를 프레임 latent들의 출처가 섞이기 때문이라는 가정을 한다
- Frame 0은 real image로부터 생성된 노이즈에서 denoising을 시작하고, frame 1~k는 같은 랜덤 가우시안 노이즈에서 시작을 한다
- 그러므로 attention 메커니즘에 따라 $\mathcal{M}$의 temproal attention layer는 provided frames을 무시하고, $\epsilon_\theta$에 의해 생성된 정보를 이용하는 경향이 있다
- 이 가설을 검증하기 위해, Single-Frame prediction (Video Infilling)을 수행
- Single-Frame prediction은 provide-frame latents로 오직 하나 Final frame을 예측하는 것이다.
- 그림의 4번째 행에서 볼 수 있듯이, 이 경우에는 temporal consistent가 유지
Repeat-and-Slide Strategy.
- 위 관측을 기반으로, proposed replacing-based baseline을 frame-by-frame generation approach로 전환
- 구체적으로, starting image latent $z^0$으로 $K$개의 frame latent를 구성
- $s_0= <s_0^0,s_0^1, ..., s_0^{K-1} >$
- 또한, step t에서 가우시안 노이즈를 clean $s_0$에 추가한 것은 아래와 같이 표기
- $s_t= <s_t^0,s_t^1, ..., s_t^{K-1} >$
- 전체 아키텍처에서 볼 수 있듯이, 디노이징 step 마다 $z_t= <z_t^0,z_t^1, ..., z_t^{K-1} >$를 $s_0= <s_t^0,s_t^1, ..., s_t^{K-1} >$로 Replace
- Repalce 방식으로 new frame’s latent $\hat{z}_0^K$를 도출
- 그리고 First frame latent를 Dequeuing하고 newly generated latent $\hat{z}_0^K$를 enquening하는 sliding operation 수행
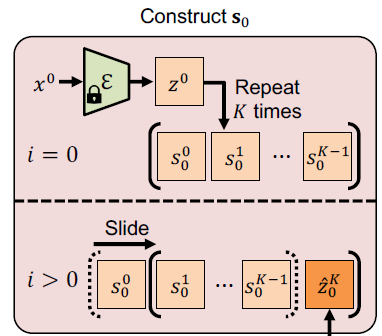
- repeat-and-slide strategy으로 Model $\mathcal{M}$은 하나의 New frame만을 예측
DDPM-based Inversion.
- $\hat{z}^T$의 초기값을 $\mathcal{N}(0, \mathbf{I})$로 부터 랜덤하게 샘플링 하는 것 대신에, $s_T$를 ($s_0$의 deffusion full step $T$)을 $\hat{z}^T$의 초기 값으로 설정
- 즉, $s_T$의 last frame $s_T^{K-1}$을 $\hat{z}_T$로 초기화
Resampling.
- Resampling technique는 본래 image inpainting task를 위해 설계됐는데, 본 연구에서는 Resampling technique을 Video DM에 적용하여 motion coherence를 높인다
- Reversed process에서 one-step denoising operation후에, one-step noise를 다시 lanet에 추가한다

4. Experiments
4.1. Datasets and Metrics
- Dataset으로는
- MUG (facial expression dataset)
- UCF101
- CHATGPT로 만든 OPEN dataset
- 생성된 비디오의 visual quality, temporal coherence, and sample diversity을 평가하기 위해
- Fr´echet Video Distance (FVD)
- text-conditioned FVD (tFVD)
- 프레임 간 움직임의 자연스러움
- subject-conditioned FVD (sFVD)
- 첫 프레임과의 시각적 일관성
4.3. Result Analysis
Ablation Study.

- Row 1 : 랜덤 noise로는 temporal consistency가 깨진다
- Row 2: DDPM-based inversion 추가하여 주어진 starting image와 Frame 1~K의 출처가 달라서 발생하는 temproal inconsistent 문제를 해결됨을 보여준다
- Row 3: 더 많은 denoising step ≠ 더 좋은 temporal consistency이 아님을 보여준다
- Row 4: Resampling (2회)을 하면 FVD, sFVD, tFVD 동시에 개선
- Row 5: Resampling을 더 강하게 적용하면 더 좋아진다

Effect of Real/Synthesized Starting Frames.
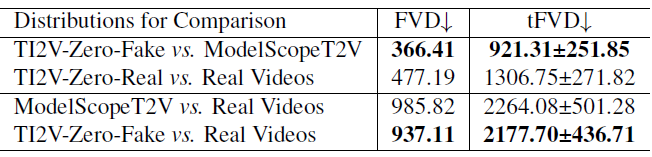
Comparison with SOTA Model.

Extension to Other Applications.
- other tasks에 적용가능
- Video infilling
- Video prediction
- long video generation
5. Conclusion
- 몇몇 한개가 존재
- pretrained T2V diffusion model에 의존하므로, 저자들은 미래에 연구를 좀 더 강력한 video diffusion foundation models을 만드는 것을 계획
- blurry or flickering 현상이 발생할 때가 있어서, video deflickering이나 image/video deblurring 방법론을 적용할 예정
- 연산량이 느리므로, faster sampling methods을 조사할 예정
Reference
https://arxiv.org/abs/2404.16306
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., "a woman is drinking water."). Existing TI2V frameworks often require costly training o
arxiv.org