Abstract.
- 정지 이미지에 애니메이션 효과를 추가하는 것은 매력적인 visual experience를 제공
- 본 논문에서는 open-domain images에 대한 dynamic content의 생성을 탐구한다
- 핵심 아이디어는, test-to-video diffusion model의 motion prior를 이용하여 image를 생성 과정에 통합하는 것
- 주어진 이미지를 Query Transformer를 이용하여 text-aligned rich image context representation로 project한다
- 그리고 좀 더 정확한 이미지 정보를 보충하기 위해서, full image를 initial noise에 concatenating한다
1 Introduction
- 최근에 text-to-video(T2V) generative model이 성공을 했다
- 본 연구의 핵심은, Conditional image를 통합하여 T2V diffusion model의 video 생성 과정을 통제하는 것이다
- 비록 VideoComposer와 I2VGen-XL이 같은 시도를 했지만, 시간적 변화가 급격하게 나타나거나 입력 이미지와의 시각적 일치도가 떨어졌다
- 이 문제를 다루기 위해서, dual-stream image injection paradigm을 제안한다
- 구성은 1) text-aligned image context projection 2) visual detail guidance로 이루어져있다
2 Related Work
2.1 Image Animation
2.2 Video Diffusion Models
- Diffusion models (DMs)은 text-to-image generation (T2I)에서 유례없는 성공을 거뒀다
- 이러한 성공을 비디오 제작에도 적용하기 위해 numerous video diffusion models (VDMs)이 개발되었다
- 비록 이러한 모델들이 좋은 결과를 보였지만, text prompts만을 semantic guidance로 사용하여 User의 의도를 정확하게 반영하지 못하거나 모호할 수 있다
- 최근에는 image condition이 조사되었다
- VideoGen, VideoComposer, I2VGen-XL
3 Method
3.1 Preliminary: Video Diffusion Models
- Diffusion models은 1) $\mathbf{x} \sim p_{data}(x)$를 Gaussian noises $\mathbf{x}_T \sim \mathcal{N}(0. \mathbf{I})$로 convert하는 forward diffusion process와 2) 이 process를 denoising하여 reverese하는 것을 학습하는 것으로 정의된다
3.2 Image Dynamics from Video Diffusion Priors
Text-aligned image context projection.
- tex embedding이 pre-trained CLIP text encoder로 도출되었기 때문에, 본 논문에서는 Image encoder를 사용하여 input image로부터 image feature를 추출
- CLIP image encoder로 부터 추출된 global semantic token $f_{cls}$가 image captions과 well-aligned되어 있지만,
- 주로 semantic level에서 visual content를 표현하고 image의 full extent를 capture하지 못한다
- 좀 더 faithful information을 얻기 위해, CLIP image ViT의 마지막 layer로부터 full visual token $F_{vis}= \{ f_i \}_{i=1}^K$을 추출

- learnable lightweight model $\mathcal{P}$로 $F_{vis}$를 final context representation으로 translate
- $F_{ctx}=\mathcal{P}(F_{vis})$
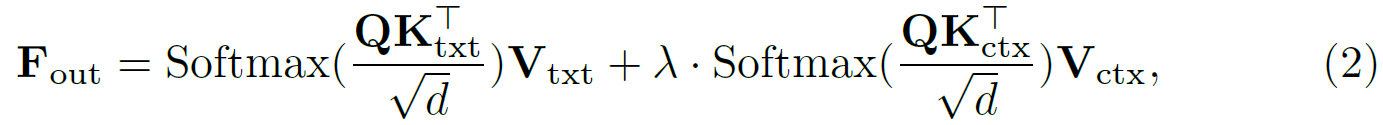
Visual detail guidance (VDG).
- conditional image를 per-frame initial noise에 concatenate하고, 그것을 denosing unet에 통과하여 guidance의 형태로 사용
4 Experiment
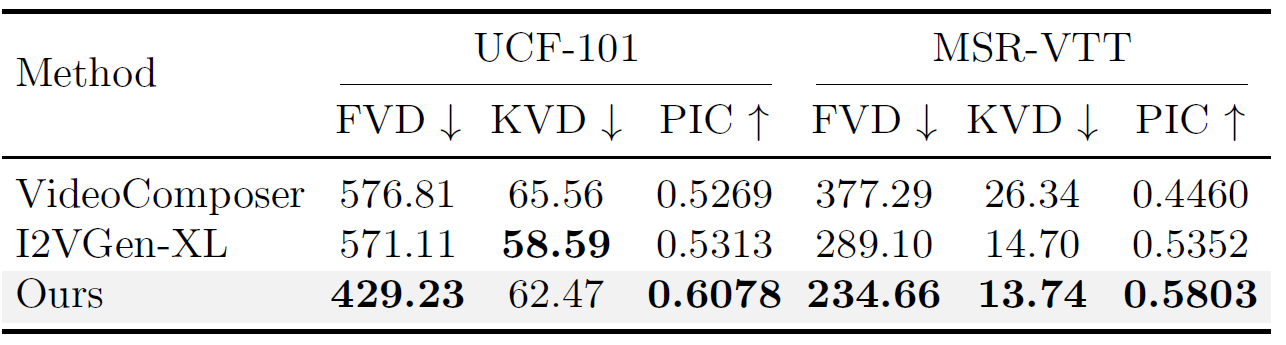
4.2 Quantitative Evaluation
Metrics and datasets.
- 공간적 영역과 시간적 영역 모두에서 합성 비디오의 품질과 시간적 일관성을 평가하기 위해
- Fréchet Video Distance (FVD)
- Kernel Video Distance (KVD)를 평가 metric으로 사용
- 추가적으로 Perceptual Input Conformity (PIC) 도입
- zero-shot generation performance 평가하기 위해,
- UCF-101
- MSR-VTT 데이터셋 사용
4.3 Qualitative Evaluation

Reference
https://arxiv.org/abs/2310.12190
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors
Animating a still image offers an engaging visual experience. Traditional image animation techniques mainly focus on animating natural scenes with stochastic dynamics (e.g. clouds and fluid) or domain-specific motions (e.g. human hair or body motions), and
arxiv.org